Shiv Shankar
Graduate Student
My research is centered around developing tools for reasoning and estimation for real-world applications. To this end I mostly work on machine learning and probabilistic models. I am also interested in grounding this research in real-world applications in sustainability and health-care.
personal info
name: Shiv Shankar


Who am i?

I AM
not mind, intelligence, ego ;
not in
ear, tongue, nose, eye ;
not sky, earth, wind, fire.
form of ETERNAL BLISS
What do I do?
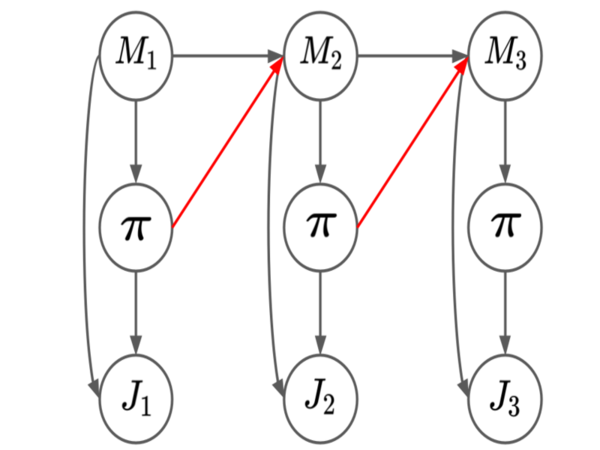
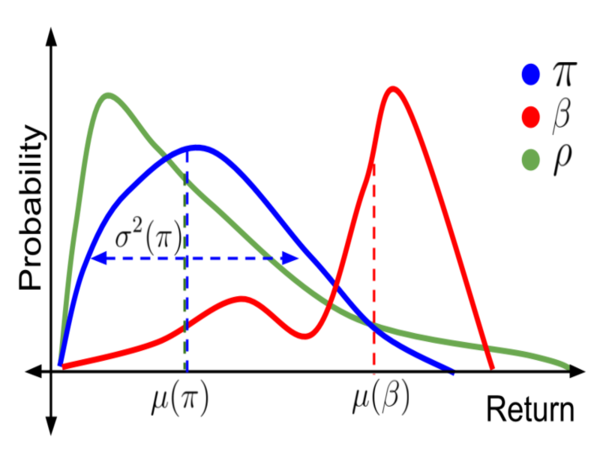
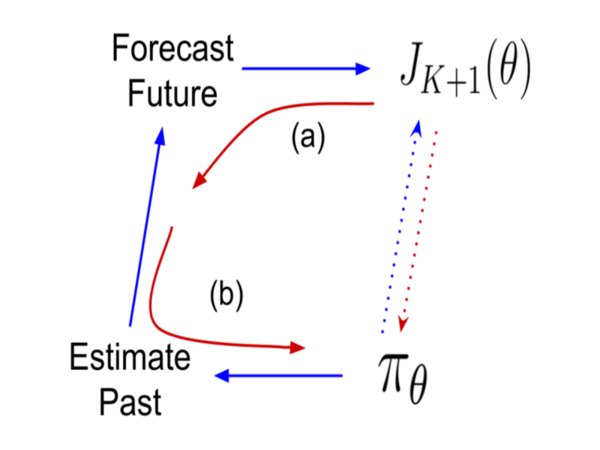
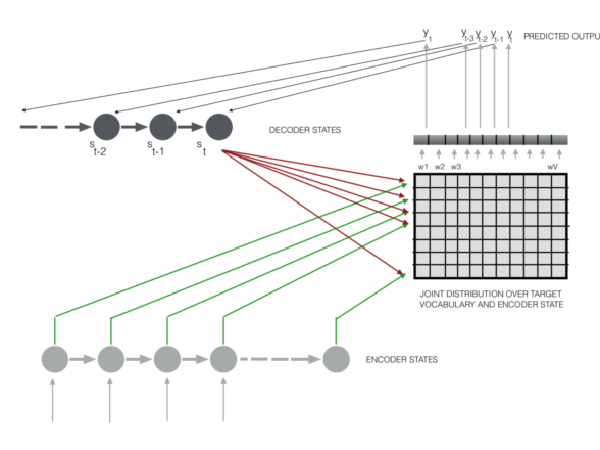
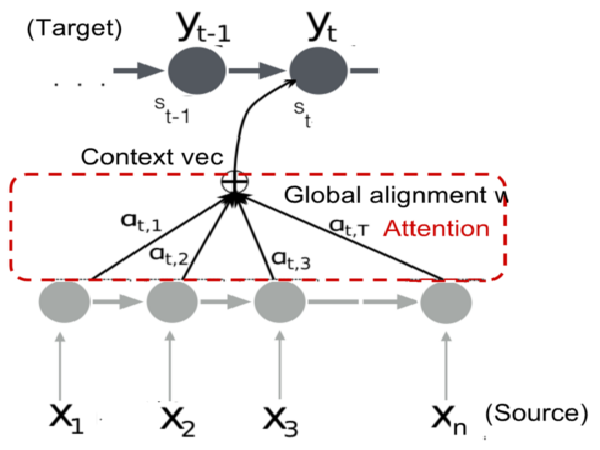
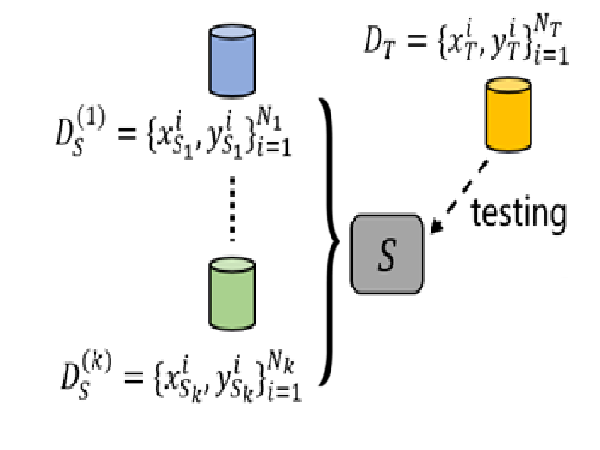
I currently play the role of a PhD student at the University of Massachusetts. I am a member of the InfoFusion Lab and also of the Machine Learning and Data Science Lab (MLDS). My research focuses on causality, variational inference and statistical estimation, with a focus on challenges of real-world applications. It also often overlaps with reinforcement learning and deep learning. My days are mostly packed with tasks and deadlines (which I inevitably miss) but I try to take out some time for fun and mischief.
What do I like?
I am curious about all kinds of scientific disciplines. A goal of mine in life is to develop some level of understanding in all other scientific fields. I am also an advocate of environmental and social impact. I can often be found discussing different research questions with students and professors alike. Occasionally, I also take out time for enjoying random movies and useless debates about philosophy, science, religion, cultures and anime.
What I'm actually good at?
I think only others can give a fair answer to this question.